Big data es hablar de equipo.
Problemática:
Básicamente, no hablaré de aspectos técnicos, voy a hablar sobre equipos, voy a describir una problemática en la que me encuentro inmerso todos los días como arquitecto y siempre es un desafío resolver, es decir, voy a escribir mi propuesta.
Mi idea es hablar sobre una problemática de aquellos que ya tienen un Big Data (no importa su tamaño), y no logran avanzar con todos esos casos de uso hermosos que los profetas del Big Big Data gritan a los 4 vientos!!! Es por ello la foto del artículo... ironía, odio a esos profetas.... que ya hablaré de ellos, por no resolver una problemática que va mas allá de los datos.

Voy a escribir sobre EQUIPOS involucrados en esta disciplina. La premisa es “como hablamos de equipo cuando hablamos de Big Data….”, aclaro que también hablare de aspectos técnicos en mis siguientes entradas, ya que también estoy preparando una wiki con manuales, laboratorios, tutoriales, etc; ya que no dejo de ser un simple y mortal técnico.
Introducción:
Desplegamos un Cluster Big Data que puede procesar todo lo que le des, guardar y hacer con los datos lo que sea…. Y ahora?.
Es muy común, y siempre hablando en el contexto de una gran compañía, que un cluster Big Data sea más que bienvenido para solucionar problemáticas con el manejo de los grandes volúmenes de datos, pero también lo es, el que traiga otros que no conocíamos relacionados a su uso, es decir, su monetización y todo lo referente al trabajo de los diferentes equipos que con el interactuan para sacar el valor.
Entonces, ¿Cuál es la problemática con los equipos?...
Basicamente, esto no se trata de una actividad donde existe un requerimiento y el área de IT lo desarrolla como suele suceder, aquí debe existir una estrecha relación entre el negocio y los "chicos IT" donde ambos desarrollan la solución desde el lugar y skill que ocupan y uno no puede vivir sin el otro. Pareciera una Boda (casamiento) implícita pero hasta que ambos no saben que lo están, las cosas no funcionarán nunca.
¿Qué quiere decir esto?
Quiere decir que generalmente, y por los perfiles que tenemos los informáticos, no es viable en un mismo momento desarrollar soluciones de alta performance de procesamiento distribuido, y adicionalmente también pensar en aspectos monetizables de esa información y el valor para el negocio, ya que los skills son diferentes y se requiere de ambos para poder llegar a buen puerto.
Uno debe ser realista y para poder explicar esto de una forma mas discreta, debemos primero entender los objetivos que perseguimos.
Cuando desplegamos un cluster Big Data, el solo contemplar sus costos asociados, nos lleva a tener una ecuación simple Cluster = Costo de Inversión entonces debo conseguir valor / retorno de esa inversión.
Por lo tanto, obtenemos ya dos variables:
Costo: Que representa mi inversión realizada en tecnología.
Valor: Que será el retorno de dicho Costo representado no solo en capacidades de procesamiento, sino también en el valor que encuentre en esos datos para hacerlos monetizables.
Pero, qué es el valor?
Definamos valor como la capacidad para generar soluciones de alta performance y alta disponibilidad, que mediante el uso de:
- Sistemas de procesamiento distribuido.
- Grandes volúmenes de datos.
- Uso de métodos matemáticos y estadísticos.
- Comunicación adecuada de los resultados.
- Subjet-matter expertise (experiencia en el área de trabajo)
Nos permita alcanzar el objetivo de generar entregables de valor, que mejoren el día a día de las decisiones o bien ayuden a la rentabilidad del negocio.
Entonces, y volviendo a esta "boda (casamiento) implícita", es inevitable hablar de los actores, ya que de alguna forma, son quienes componen el equipo de trabajo.
Boda (casamiento) de actores

En el ecosistema Big Data, encontraremos dos grandes actores:
Por un lado los Data Scientist quienes buscaran resolver mediante el uso de técnicas descriptivas y estadísticas, el comprender y analizar fenómenos reales con el uso de los datos.
Por otro lado, tendremos a los Data Engineers, quienes tendrán el trabajo de capturar, recolectar y procesar grandes volúmenes de datos que sería imposible hacerlo en los medios convencionales de almacenamiento y procesamiento. Aquí entra un atributo importante.... construir soluciones de alta performance.
Los resultados de valor, deben surgir del equipo y el trabajo de estos dos grupos, donde uno esta más abocado al trabajo de encontrar el valor en los datos, mientras que el otro en construir aplicaciones de alta performance que puedan facilitar dichos trabajos.
Es aquí donde de alguna forma llegamos a una buena definición:
Los Data Data Scientist (D.S) estan en el camino de descubrir, predecir y describir hechos del mundo real. Para ello es primordial un skill avanzado en matemáticas, estadísticas; y un perfil más bien bajo en desarrollo de software y programación.
Los Data Engineers (S.E o D.E) están en el camino orientado a desarrollar aplicaciones de alta performance que puedan procesar, almacenar y mover cantidades inimaginables de datos.
El punto en común entre ambos, es que los dos deben poseer un conocimiento avanzado en el área sobre la que se trabajara (Subjet-matter expertise).
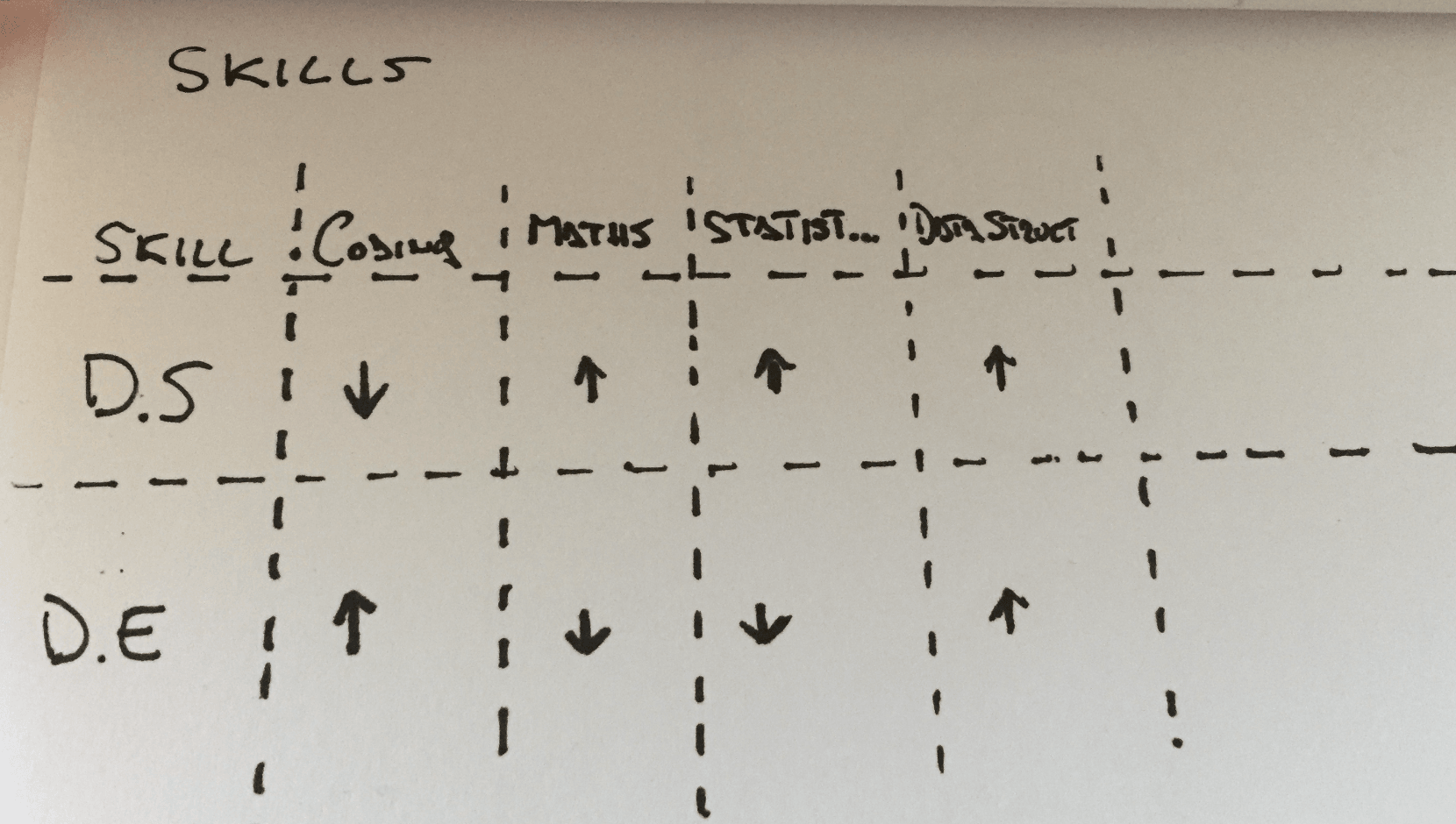
Adicionalmente a esto, existen las marcadas diferencias entre un D.S y un D.E.
Ambas diferencias significan, en la práctica, que los desarrolladores y los científicos de datos a menudo tienen problemas para trabajar juntos. Las prácticas estándares de desarrollo de software no funcionan realmente para el modo de trabajo exploratorio del científico de datos porque las metas son diferentes. La introducción de revisiones de código y una solución ordenada, no funcionaría para los científicos de datos y los ralentizaría. Del mismo modo, la aplicación de este modo exploratorio a los sistemas de producción tampoco funcionará si se busca desarrollar soluciones de alta performance.
Si analizamos el flujo de una arquitectura hasta la visualización de los datos, podremos ver como impactan los skills de uno y de otro:
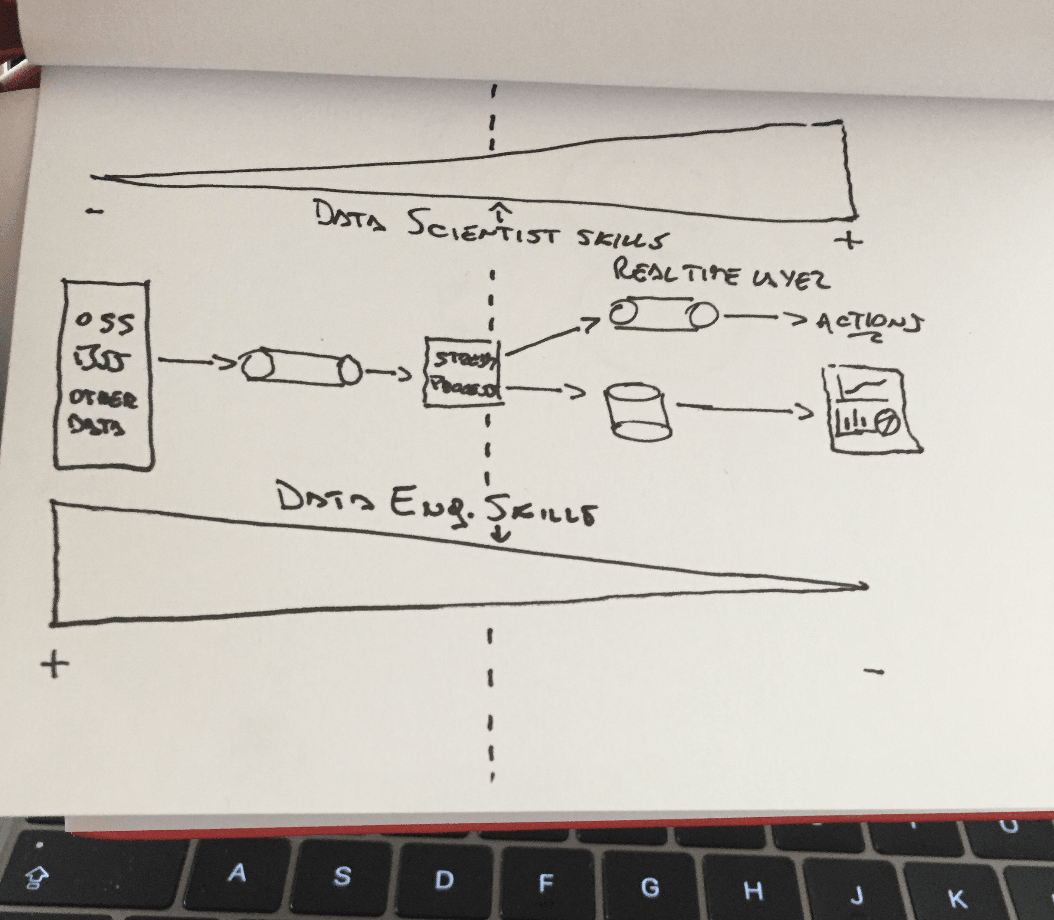
Observando que en los procesos de captura y procesamiento de la arquitectura, son más requeridos los roles de D.E pero a medida que nos vamos acercando al valor de los datos, son más valiosos los conocimientos de un D.S.
Ahora bien, no hemos resuelto como podemos hacer que estos dos universos tan diferentes jueguen a obtener un mismo objetivo.
Entonces, ¿cómo podemos estructurar la colaboración para que sea más productiva para ambas partes??
Mediante requerimientos escritos en documentos ?
Definitivamente creo que esta no es una solución, ya que de alguna forma este método lo que plantea es mantener separados a los equipos y conectados mediante documentación. Ya sabemos como termina esta situación.
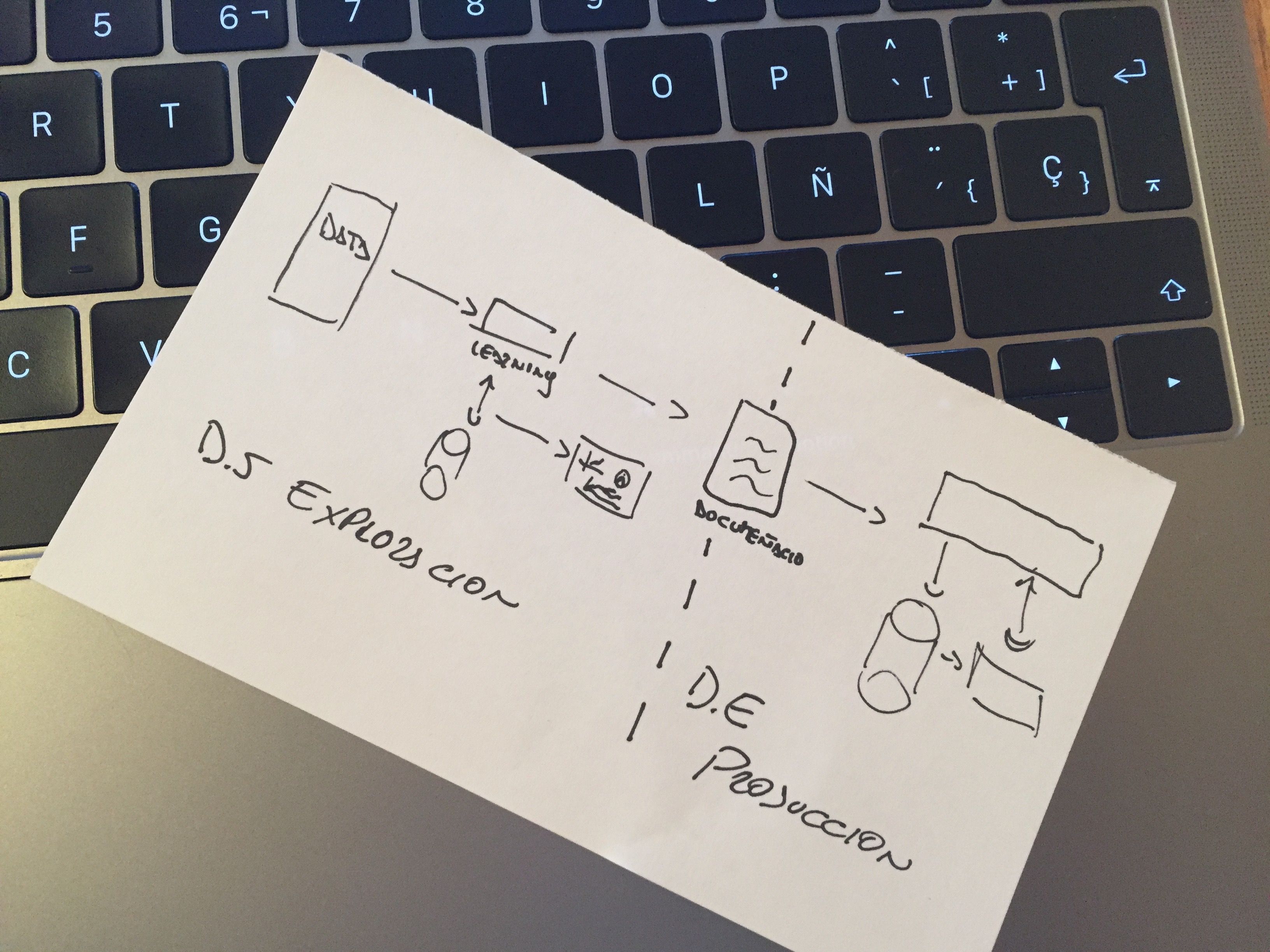
Si bien este método puede funcionar (lo dudo mucho en mi humilde opinión), es un método que no resuelve la necesidad de ser ágiles y resolver con velocidad los requerimientos.
Uniendo el agua y el aceite ?
Puede que suene un tanto a locura, pero claramente si hablamos de unir, esto debe significar el todo por el todo y sin rodeos.
Existe una gran diferencia de perfiles, pero dentro del mismo departamento de IT lo existe también, solo que desde hace tiempo, observo que esta diferencia se acentúa cuando ademas de esto, existen separaciones organizativas que promueven esta separación (estructura, procesos con "mas documentos", etc).
Los componentes de este sistema (los D.S y los D.E) son muy diferentes, pero por separado, esto sería un sistema donde un engranaje no hace girar al otro.

Creo que cada vez es más común, y viendo el mercado en mi entorno lo confirmo, que estos perfiles comenzarán con el correr del tiempo a tener más cosas en común (D.S con conocimientos de software y D.E con más conocimientos en métodos matemáticos).
Adicionalmente a esto, y ya siendo un hecho visible en muchas de las grandes compañías, ya existe en el "C" level de la estructura la figura del Chief Data Officer, y los equipos de Data Scientist y Data Engineer conviven bajo un mismo grupo de trabajo y no como entes separados.
Es imposible pensar en que una pieza del motor mueva a la otra, sin que una de ellas se encuentre dentro del mismo motor. El equipo de datos de una compañía, debe ser uno y no compuesto en mi humilde opinión por partes de esta.
Muchas gracias.
Martin.
Subscribe to Martin Gatto
Get the latest posts delivered right to your inbox