Data Lake is more than ‘dump your data here’.
Last week I was reading the Hortonworks Carrers page and I seen something interesting in the job´s requirements.
The description has some points related with job´s requirements, but one key requirement take my attention...."Data Lake is more than 'dump your data here' ".
I thought about it for a second and the need to write about this won, because I think this is an interesting problem to analyze if I compare this concept with the big data evangelists message... "put everything here and next we'll see what can we do with it....".
The first point is.... THIS IS TRUE MY FRIENDS, data lake is not only 'dump your data here'
When we talk about Big Data we really talk about big problems if we don't do our work in a good way.

Look at this image.... I think this is a real data lake when you don't think in how can you archive your data to use in the future ( "put everything here and next we'll see what can we do with it...." ). Tell me, can you imagine find something here when you need something specific?.
The data discovery processes executed by data Scientists need something from the Data Engineers, these "things" are the order and the capacity to make the data understandable to others.

Please, just take a look to this two previous pics. You have a very big mountain (or lake) of trash, and in the next pic you have a very big quantities of trash ordered, separated and classified.
Now, you have to think on those pics like a data lake, and think in the processes you'll have to make to find something in those two scenaries. It`s true, we prefer maybe the scenari where we have our data working for us in order because "the data lake is no only 'dump your data here' (second pic).
So.. where I want to go with this and what's the solution for this problem?.
Solution = Order, data consistency and grouping of data by domain

In the companies, we have our systems built around to architecture frameworks. This Architecture Frameworks, makes rules and methodologies for systems, processes, data and integrations.
For example: Telcos have the TM Forum Framework where you can look standards for applications, solutiones, integrations and data.
The Information Framework (SID) talk about data levels. The level One, it´s the SID domain where group the principal domains: Customer, Services, Products, Resources, Market, etc.....
Each domain, have Abe´s (customer, customerBill, CutomerOrder) and this abe´s has data entityes grouped to represent an specific representation of the data domain.
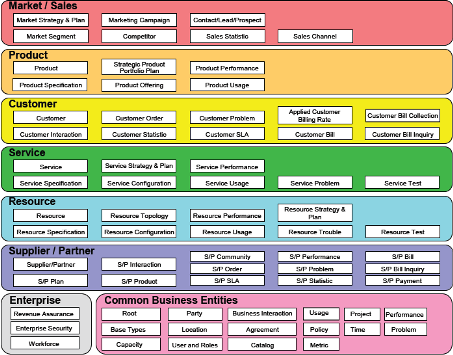
Let's apply this knowledge to a data lake, and may be we can use this metodology to make more efficient our data discovery processes but before, make more efficient our data archiving processes:
For example:
- Maybe you have to archive data about your Products, so you can save this data in the "product" data base if you are working with hive or impala.
- If you need to archive data from your billing, you have to use de Customer data base, because this information is related with de customer account data, and the customer data.
- But... what happen if I need to archive the data from logs and my services´s usage?. This information is related with the resource usage, so we have a place for this data too in the framework.
We also have other benefits if we make more ordered, and grouping our data by domain in the Data Lakes :
- Governance: The data owners in general are grouped by domains also, so the governance is more easy to manage and define in this case.
- Security: You can manage your security policies in Ranger (if you are using Hortonworks and hive) more efficiently grouping their policies by groups of domains and tables within each of the data bases.
- Clarity in the matter: You have to know " which domain has the data I need", so is more easy to find something you need. In the concept "put everything here and next we'll see what can we do with it...." you have a tiring job first by finding what you need and then being able to pull some value out of what you find.
- Common Language: Not all people in the company who work with the data lakes, will know what you have in this very big place, but is realistic they understand the concepts about the Domains and his definitions.
- Business Processes and Applications: Could be a good way to understand, how the data lake has a relation with the company's processes and the applications that support this processes and the data inside this apps.
Thanks :)
King Regards
Martin.
Subscribe to Martin Gatto
Get the latest posts delivered right to your inbox