Lessons learned on using CDC for real-time integrations
The first question is... "is a real-time integration necessary" and the answer will always be YES. Why? This is because the business in its rationale considers that information in real time is money and that is its goal, so IT architecture must be the facilitator of that goal. Of course as architects we can dissuade them from alternative solutions, but at the end of the day, if they need the data in real time, that's how it should be.
Now, since the work of going for a real-time integration solution is unavoidable, my intention here is to highlight some issues that are important to take care of for the health of the architecture and ours.
About the source Database:
- Be very careful with storage: As obvious as it may seem, you should keep in mind that for every database transaction that is created, one or more cdc transactions will be created. This implies that you must have within your reach a correct measurement of the data volumes that this source generates, but even more so, the number of transactions by type. For example, an update transaction does not generate a new record in the table to be replicated, but will generate two cdc transactions (cdc records) in the sql server cdc table. Also, you have to work as a team with your team of DBAs to manage the debugging of that information from time to time. The tables will grow, and when they do the performance will decrease (in the case of cdc using tables like Sql Server).
- Keep track of the number of sessions that the integration solution will create in the database and be aware that the latter can withstand this pressure.
- Do not dismiss networking issues, the volume of data per unit of time to be moved must be supported by the network bandwidth. In general this is not a problem, but it is an item to consider.
- Understand and keep in mind the number of queries per second that the database supports. This is a very important item that translates into the pressure that the database will support.
- Always try to do the integrations using logs and avoid whenever you can the use of tables. There are different solutions and this varies a lot depending on the database you have. But if there is the option to choose, it will be the best option to opt for an integration through logs (for example: redologs in the case of Oracle), since this will help to avoid latency problems, objects blocked by other tasks, etc.
About the integration solution:
All solutions will fulfill the task of integrating the data. The question that will make a real difference between one and the other is the capacity that the solution has to manage the adversities that will arise in the maintenance of the solution that we build.
-
Initial Loads / Bulk loads: Keep in mind that the start of the project, when everything is ready, will begin with an initial load of data from the source to the target. It is desirable that the integration solution has the ability to manage this initial load easily.
Keep in mind even more, that when you think that everything is going great and everything works fine, something will happen that will ruin the consistency between what you have at the source and at the destination and this will lead you to the process of having to regenerate that table, tables or the entire database, and you need the solution to handle this incremental load from a specific point or do it from scratch. Keep in mind also, that it is possible that you cannot stop the productive environment (blackout) and you must do this at the same time that the database to be replicated receives transactions.
IN SUMMARY: Take care that the solution you choose manages this process efficiently (the initial load) and contemplates the particular issues related to the usability of your database. -
That the solution allows you to work with regular expressions to define integration tasks that include the selection of objects from the database by patterns and not by their exact name.
-
That your integration solution does not require column-to-column mapping. Let her take care of finding the coincidences of integrating column 1 with column 1 of the same table.
-
It must be possible to manage schema changes (alter column, drop column) and maintain the continuity of your integration. But even more important is that when it detects that a column is no longer there or a new column was created, it replicates this change in the destination. Especially, when the source database is different from the destination one (eg: Sql server to snowflake).
-
That with the first execution, create the tables in destination, and replicate the same structure as in the source. Especially primary keys. The latter is important, since in general the primary keys are a necessary issue in case of requiring the merge of transactions (snowflake for example).
-
That supports automatic scaling of your infrastructure. There will always be contingencies that require it.
-
That the licensing scheme adapts to the new market requirements (pay per use, price per hour, SaaS) and not old license schemes such as core licenses, which imply in the future that you negotiate more licenses with the provider context of a specific need for escalation and de-escalation.
Architecture Design Patterns:
In general, this section is not very complex, but no less important.
It tries to manage and design an architecture that from the conception of its design is fault tolerant. Some of these issues are covered by some of the previous points (for example: automatic scaling). Even so, it is important to reflect that considering all the previous points, we must make sure that everything continues working in the event of a problem, or at least not everything stops working.
I like at this point to highlight my recommendation to create a semantically decoupled architecture according to its responsibilities.
This will give the benefit of having assets that are fault tolerant, resilient and of a management of the entropy of the system more agile and clear.
To do this, we can choose to use a messaging broker or a storage account that allows us to download the data first as a broker offset or as a file in a storage account of our cloud subscriber. This will help us to have a recovery point in case of errors (since the data is stored for a while in the broker or in the storage account) and additionally it will allow us to play with the use of different clients deployed in different availability zones and that these data can be used if required, by other consumers (lambda architecture principle)
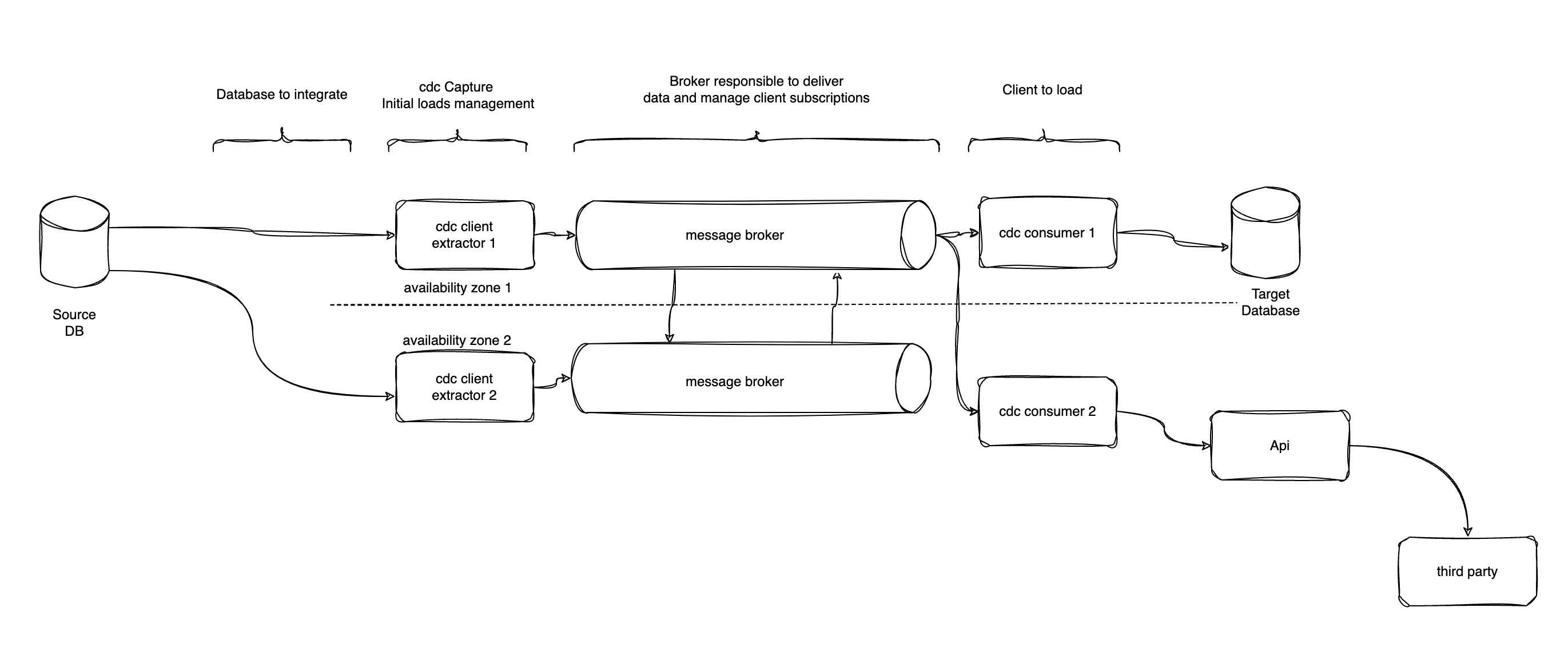
These are some, but not all of the issues I would recommend looking out for. Of course, you can always add more, but it's important to consider the type of solution you want. From my experience, these are the basic things and on top of that it is possible to add more complexity and functionality.
I want to thank you for your time.
Martin.
Subscribe to Martin Gatto
Get the latest posts delivered right to your inbox